2)파이썬 크롤링으로 네이버 환율,금 시세,유가,증시 등등 정보 추출하기(Beautifulsoup - select_one)
파이썬, beautifulsoup 라이브러리 사용합니다
beautifulsoup의 select_one()을 사용합니다 - 한가지 단위 데이터
정보를 얻고자 하는 사이트의 html 구조를 분석하여 원하는 내용을 추출합니다
1 2 3 4 5 6 7 8 9 10 11 12 | from bs4 import BeautifulSoup import urllib.request as req url = "https://finance.naver.com/marketindex" res = req.urlopen(url) soup = BeautifulSoup(res, "html.parser") price = soup.select_one("a.head.usd > div.head_info > span.value").string print("usd/krw =", price) | cs |
설명
----------------------------------------------------------------------------------------------------
from bs4 import BeautifulSoup
-> BeautifulSoup 라이브러리를 사용합니다
(HTML 및 XML 문서 를 구문 분석하기위한 Python 패키지입니다)
- 설치는 터미널에서(우분투 리눅스 기준) pip3 install beautifulsoup4
----------------------------------------------------------------------------------------------------
import urllib.request as req
->urllib.request는 URL을 가져오기 위한 파이썬 모듈입니다
- as req 는 urllib.request모듈을 대신할 이름을 지정하는것 입니다 (편의성을 위해)
(req는 사용자가 마음대로 이름을 바꿔도 됩니다)
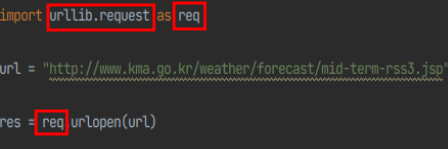
빨간 네모박스 urllib.request , req 모두 urllib.request 모듈을 의미합니다
res = req.urlopen(url)를 res = urllib.request.urlopen(url)로 바꿔도 정상작동합니다
url = https://finance.naver.com/marketindex
https://finance.naver.com/marketindex/
환전 고시 환율 2022.08.24 19:23 하나은행 기준 고시회차 461회
finance.naver.com
-> url에 접속할 http주소를 넣습니다 (네이버 금융)
----------------------------------------------------------------------------------------------------
res = req.urlopen(url)
-> urllib.request 모듈의 urlopen기능으로 url(네이버 금융)을 열고 res에 넣습니다
----------------------------------------------------------------------------------------------------
soup = BeautifulSoup(res, "html.parser")
-> BeautifulSoup라이브러리로 res에 담겨있는 url(네이버 금융)을 html.parser으로 구조를 분석하고 soup에 넣습니다
----------------------------------------------------------------------------------------------------
price = soup.select_one("a.head.usd > div.head_info > span.value").string
-> 위에서 분석한 정보가 담겨있는 soup에 select_one기능으로 a.head.usd > div.head_info > span.value에 있는 string(문자열)을 추출하고 price에 정보를 넣습니다
구글크롬(검색엔진)기준으로 정보를 얻고자 하는 사이트에서 ctrl + shift + c 를 누르시면 해당 페이지의 html 구조를 볼 수 있습니다
ctrl + shift + c를 한 사진
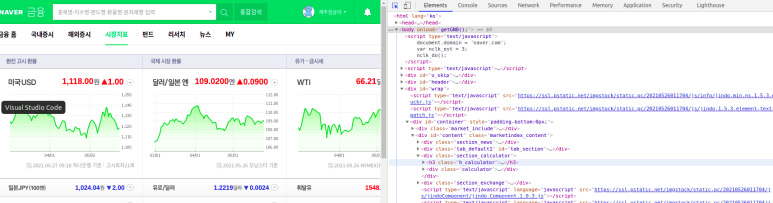
(얻고자 하는 정보에 마우스로 클릭하시면 해당 정보의 html구조 위치로 이동됩니다)
a.head.usd > div.head_info > span.value 을 해석하자면

a안에 head안에 usd를 찾고 그 아래에 속한 div안에 head 안에 info를 찾고 그 아래에 속한 span안에 value을 찾아라 입니다
(a, div, span은 html이라는 프로그램 언어에서 사용하는 태그입니다)
div.head_info 에서 div.head_info.point_dn대신 div.head_info을 입력한 이유는 환율이 상승할때와 하락할때 각각 point_dn(하락할때) point_up(상승할때)으로 html구조가 바뀌는 시스템이라 뒷부분은( point_ ) 생략하는게 좋습니다
응용
달러 환율 변동폭 얻기
a.head.usd > div.head_info > span.change
달러 환율 상승 또는 하락 정보 얻기
a.head.usd > div.head_info > span.blind
*다른 국가의 환율또는 금 시세를 얻고싶을때 a.head. <-이 부분을 바꾸시면 됩니다
a.head.usd > div.head_info > span.value - 미국,
a.head.jpy > div.head_info > span.value - 일본,
a.head.cny > div.head_info > span.value - 중국,
a.head.gold_domestic > div.head_info > span.value - 국내 금 시세
----------------------------------------------------------------------------------------------------
print("usd/krw =", price)
<- 내용물(price)를 출력합니다
출력내용
