우분투 리눅스와 파이썬, beautifulsoup 라이브러리를 사용합니다
beautifulsoup의 find를 사용합니다 - 한가지 단위의 데이터 추출
소스코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | from bs4 import BeautifulSoup import urllib.request as req url = "http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp" res = req.urlopen(url) soup = BeautifulSoup(res, "html.parser") title = soup.find("title").string wf = soup.find("wf").string print(title) print(wf) | cs |
설명
----------------------------------------------------------------------------------------------------
from bs4 import BeautifulSoup
-> BeautifulSoup 라이브러리를 사용합니다
(HTML 및 XML 문서 를 구문 분석하기위한 Python 패키지입니다)
- 설치는 터미널에서(우분투 리눅스기준) pip3 install beautifulsoup4
----------------------------------------------------------------------------------------------------
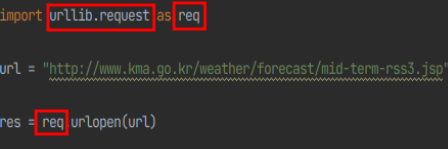
import urllib.request as req
->urllib.request는 URL을 가져오기 위한 파이썬 모듈입니다
- as req 는 urllib.request모듈을 대신할 이름을 지정하는것 입니다 (편의성을 위해)
(req는 사용자가 마음대로 이름을 바꿔도 됩니다)
빨간 네모박스 urllib.request , req 모두 urllib.request 모듈을 의미합니다
res = req.urlopen(url)를 res = urllib.request.urlopen(url)로 바꿔도 정상작동합니다
url = http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp
-> url에 접속할 http주소를 넣습니다
url주소로 접속한 사이트
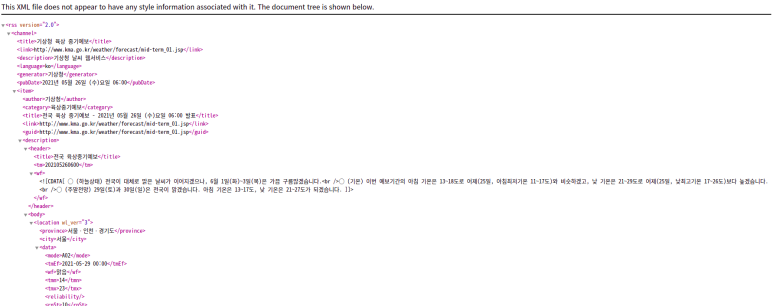
기상청에서 RSS를 지원합니다(XML형식)
----------------------------------------------------------------------------------------------------
res = req.urlopen(url)
-> urllib.request 모듈의 urlopen기능으로 url(기상청)을 열고 res에 넣습니다
----------------------------------------------------------------------------------------------------
soup = BeautifulSoup(res, "html.parser")
-> BeautifulSoup라이브러리로 res에 담겨있는 url(기상청)을 html.parser으로 구조를 분석하고 soup에 넣습니다
----------------------------------------------------------------------------------------------------
title = soup.find("title").string
wf = soup.find("wf").string
-> 위에서 분석한 정보가 담겨있는 soup에 find로 title과 wf태그의 string(문자열)을 추출하고 각각 title과 wf에 넣습니다
(URL로 들어가서 원하는 정보의 태그를 soup.find("여기에").string 입력하면 됩니다
url(기상청)내용 사진

----------------------------------------------------------------------------------------------------
print(title)
print(wf)
<- 내용물(title, wf)를 출력합니다
출력내용

'Python' 카테고리의 다른 글
| 파이썬 cron으로 정기적으로 프로그램 실행하기 (0) | 2022.09.07 |
|---|---|
| 5) 파이썬 API으로 전세계 날씨정보 얻기 (0) | 2022.09.05 |
| 4)파이썬 크롤링으로 페이지내 모든 정보를 얻기 (0) | 2022.09.03 |
| 3)파이썬 크롤링으로 뉴스정보 수집하기(Beautifulsoup - select) (1) | 2022.09.02 |
| 2)파이썬 크롤링으로 네이버 환율,금 시세,유가,증시 등등 정보 추출하기(Beautifulsoup - select_one) (1) | 2022.08.24 |



