1,2,3보다 좀더 심화된 내용입니다
어떤 페이지내에서 하위페이지를 포함하여 사진,파일등등을 추출합니다
파이썬, beautifulsoup 라이브러리 사용합니다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 | from bs4 import BeautifulSoup from urllib.request import * from urllib.parse import * from os import makedirs import os.path, time, re proc_files = {} def enum_links(html, base): soup = BeautifulSoup(html, "html.parser") links = soup.select("link[rel='stylesheet']") links += soup.select("a[href]") result = [] for a in links: href = a.attrs['href'] url = urljoin(base, href) result.append(url) return result def download_file(url): o = urlparse(url) savepath = "./" + o.netloc + o.path if re.search(r"/$", savepath): savepath += "index.html" savedir = os.path.dirname(savepath) if os.path.exists(savepath): return savepath if not os.path.exists(savedir): print("mkdir=", savedir) makedirs(savedir) try: print("download=", url) urlretrieve(url, savepath) time.sleep(1) return savepath except: print("다운 실패: ", url) return None def analyze_html(url, root_url): savepath = download_file(url) if savepath is None: return if savepath in proc_files: return proc_files[savepath] = True print("analyze_html=", url) html = open(savepath, "r", encoding="utf-8").read() links = enum_links(html, url) for link_url in links: if link_url.find(root_url) != 0: if not re.search(r".css$", link_url): continue if re.search(r".(html|htm)$", link_url): analyze_html(link_url, root_url) continue download_file(link_url) if __name__ == "__main__": url = "https://docs.python.org/ko/3/" analyze_html(url, url) | cs |
목표
----------------------------------------------------------------------------------------------------
정보를 얻고자 하는 페이지 내 링크,사진등등 모든 정보를 수집합니다
재귀적으로 html 페이지를 처리합니다
1) html을 분석합니다
2) 링크를 추출합니다
3) 파일을 다운받습니다
4) 파일이 html이라면 재귀적으로 1)으로 돌아가서 순서를 다시 실행합니다
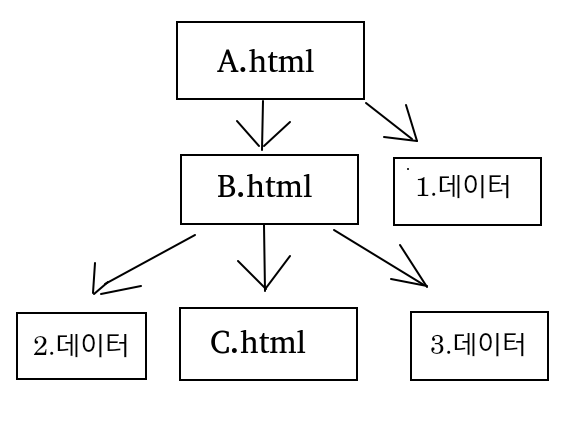
설명
----------------------------------------------------------------------------------------------------
from bs4 import BeautifulSoup
from urllib.request import *
from urllib.parse import *
from os import makedirs
import os.path, time, re
-> BeautifulSoup 라이브러리를 사용합니다
(HTML 및 XML 문서 를 구문 분석하기위한 Python 패키지입니다)
- 설치는 터미널에서(우분투 리눅스 기준) pip3 install beautifulsoup4
-urllib.request는 URL을 가져오기 위한 파이썬 모듈입니다
-urllib.parse는 URL문자열을 구성 요소(주소 지정 체계, 네트워크 위치, 경로 등)로 분리하고, 구성 요소를 다시 URL 문자열로 결합하고, 《상대 URL》을 주어진 《기본 URL》에 따라 절대 URL로 변환하는 파이썬 모듈입니다
-from os import makedirs
import os.path, time, re
-> 는 파일(디렉토리)를 생성,삭제등등 파일을 관리하는데 도움이 되는 파이썬 모듈입니다
----------------------------------------------------------------------------------------------------
proc_files = {}
->전역변수(코드 어디에서든 사용가능한)를 선언과 동시에 초기화합니다
이미 분석한 HTML 파일인지 구분하기 위한 변수입니다
----------------------------------------------------------------------------------------------------
html을 분석하고 링크를 추출하는 함수입니다
1 2 3 4 5 6 7 8 9 10 11 | def enum_links(html, base): soup = BeautifulSoup(html, "html.parser") links = soup.select("link[rel='stylesheet']") links += soup.select("a[href]") result = [] for a in links: href = a.attrs['href'] url = urljoin(base, href) result.append(url) return result | cs |
->BeautifulSoup 라이브러리로 html을 파싱하여 soup에 넣습니다
links = soup.select("link[rel='stylesheet']")
links += soup.select("a[href]")
->BeautifulSoup의 select기능으로 링크와 url(href 속성)를 추출하여 links에 넣습니다
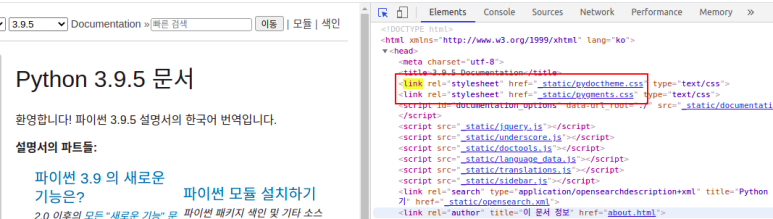
result = []
for a in links:
href = a.attrs['href']
url = urljoin(base, href)
result.append(url)
return result
->result 변수(리스트형)을 선언하고
for으로 links(위에서 얻는 링크와 url)의 갯수만큼 반복합니다
href = a.attrs['href']의 attrs는 BeautifulSoup 라이브러리의 기능으로 html의 속성을 지정해서 추출할 수 있습니다(여기에선 href를 추출합니다)
url = urljoin(base, href)
-> from urllib.parse import * 의 기능으로 url의 상대경로를 절대경로로 변경해줍니다
절대경로로 바꿔줘야지 오류없이 작동합니다
*상대경로 = 현재위치를 기준으로 삼고 상대 찾는 경로
*절대경로 = 동일한 위치를 기준으로 상대를 찾는 경로
result.append(url)
-> result에 append기능으로 url(위에서 절대경로로 바꾼 url)을 추가합니다
----------------------------------------------------------------------------------------------------
인터넷에 있는 파일들을 다운받는 함수입니다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | def download_file(url): o = urlparse(url) savepath = "./" + o.netloc + o.path if re.search(r"/$", savepath): savepath += "index.html" savedir = os.path.dirname(savepath) if os.path.exists(savepath): return savepath if not os.path.exists(savedir): print("mkdir=", savedir) makedirs(savedir) try: print("download=", url) urlretrieve(url, savepath) time.sleep(1) return savepath except: print("다운 실패: ", url) return None | cs |
url을 기반으로 파일명을 결정하고 폴더를 생성합니다
o = urlparse(url)
-> urlparse 기능으로 url을 파싱하고 o에 넣습니다
savepath = "./" + o.netloc + o.path
->o 안에있는 url 정보중에 netloc과 path을 savepath에 넣습니다
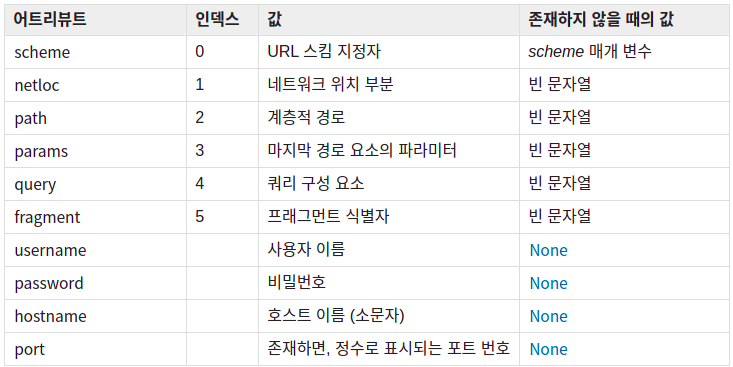
if re.search(r"/$", savepath):
savepath += "index.html"
->import os.path, time, re 모듈의 기능입니다
re.search는 (기준 , 문자열)가 있을때 문자열에 기준과 동일한것이 하나라도 있을때 참입니다
예 -> re.search(a, ab) = 참
예 -> re.search(a, bc) = 거짓
r"/$" -> 몇몇프로그래밍 언어에선 특수 시퀸스라는것이 있습니다
/의 뒤에오는 몇몇 문자들은 문자로 인식하지 않고 특수 시퀸스처리되는 경우가 있습니다 이런것을 방지하기위해 r을 앞에 입력해주면(import os 기능) " /$ " 을 인식하게 됩니다
savedir = os.path.dirname(savepath)
-> os.path.dirname은 svaepath의 경로명을 반환합니다
예시-> 바탕화면에 A라는 폴더 안에 B.txt라는 텍스트 파일이 있을때
test = os.path.dirname(B.txt)를 하면 바탕화면/A 라는 경로를 얻고 test에 넣습니다
- savedir은 파일(디렉토리)의 이름을 생성하거나 얻은 정보를 저장할 위치(파일명)을 찾을때 사용합니다
if os.path.exists(savepath): return savepath
if not os.path.exists(savedir):
print("mkdir=", savedir)
makedirs(savedir)
->
if와 if not은 서로 반대되는 개념입니다 if는 참일때 if not은 거짓일때만 아래 코드가 실행됩니다
예시
if (참)
-코드 실행-
if (거짓)
-실행안됨-
if not (참)
-실행안됨-
if not (거짓)
-코드 실행-
if os.path.exists(savepath): return savepath
->savepath 데이터가(파일,폴더등등) 존재하는지 판단합니다
if not os.path.exists(savedir):
print("mkdir=", savedir)
makedirs(savedir)
-> 만약 데이터가 존재하지 않는다면 svaedir에 들어있는 이름으로 새로 생성합니다
try:
코드~~
except:
코드~~
->try , except는 예외처리 문법입니다
try의 코드가 실행되다가 에러가 발생하면 except의 코드가 실행됩니다
try, except는 에러가 발생할 수 있는 코드를 실행할때 유용합니다
일반적으로 프로그램실행중 에러가 발생하면 프로그램의 동작이 중지됩니다
하지만 try와 except를 사용하면 동작이 중지되지 않고 에러를 처리할 수 있습니다
try와 except를 응용하여 아래 사진과 같이 사용 할 수도 있습니다
*try와 except로 만든 문자 중복횟수 확인 코드
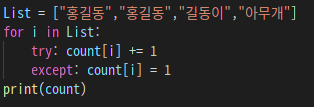
try ,except 응용

결과
*이외에도 사용자한테 입력값을 받을때 숫자를 입력해야되는데 문자를 입력했을때 등등
잘 사용한다면 유용한 문법입니다
* 파일을 다운받는 코드
try:
urlretrieve(url, savepath)
time.sleep(1)
return savepath
except:
print("다운 실패: ", url)
return None
-> urlretrieve은 urllib.request의 기능으로 정보를 얻고싶은 url주소에서 데이터를 다운받는 기능입니다
urlretrieve(정보를 얻고싶은 url주소, 저장할 위치)
->time.sleep()은 ()안의 숫자만큼 프로그램동작을 중지(대기) 합니다
1초간 중지하는 이유는 너무 빠른속도로 데이터를 받고 다른 사이트로 이동하면 로딩속도때문에 해당 사이트의 정보를 얻지 못하는 경우가 있습니다
*인터넷 속도에 따라 조절하세요
또한 몇몇 사이트에서는 빠른속도로 정보,접속요청을 하는 경우 차단하는 경우가 있습니다
*처음에는 잘 작동하다가 에러가 발생하는 경우 대기시간 숫자를 높게 설정해보세요
*주의할점
접속하고자 하는 사이트에 정보를 요청하거나 접속을 요청하는 경우 빠른속도로 반복적인 요청을 하는것은 좋지 않습니다
해당 사이트의 서버에 부하가 발생 할 수 있습니다
비슷한 방식의 해킹기법으론 Dos,DDos(디도스 공격)이 있습니다
많은양의 요청을 서버에 보내서 서버에 부하가 발생하게 하는것이 Dos,DDos(디도스 공격)입니다
*이러한 크롤링 프로그램을 만들때는 이러한 점을 인지하고 해당 서버에 부하가 걸리지 않게 적당한 대기시간을 설정하는게 좋습니다
----------------------------------------------------------------------------------------------------
*html을 분석하고 다운받는 함수입니다
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | def analyze_html(url, root_url): savepath = download_file(url) if savepath is None: return if savepath in proc_files: return proc_files[savepath] = True print("analyze_html=", url) html = open(savepath, "r", encoding="utf-8").read() links = enum_links(html, url) for link_url in links: if link_url.find(root_url) != 0: if not re.search(r".css$", link_url): continue if re.search(r".(html|htm)$", link_url): analyze_html(link_url, root_url) continue download_file(link_url) | cs |
-> savepath = download_file(url) savepath에 url주소를 넣습니다
if savepath is None: return
if savepath in proc_files: return
proc_files[savepath] = True
-> is는 오브젝트가 같은 종류인지 판단하기위해 사용됩니다
예) a is b -> a와 b가 같은 오브젝트인 경우 True
-> in은 배열에 특정한 값이 있는지 확인하기 위해 사용됩니다
예) a = [1,2,3]
print(1 in a) = 참 , print(2 in a) =참 , pinrt( 4 in a) =거짓
if savepath is None: return
if savepath in proc_files: return
-> 저장할 데이터가 없는경우에는 저장하는 동작을 생략하는것과
이미 저장된 데이터를 중복저장하는것을 막는 역할을 합니다
(이 코드가 실행되면 데이터를 저장하는 동작이 실행되지 않습니다)
proc_files[savepath] = True
-> proc_files는 위에서 선언한 전역변수입니다 이미 분석한 파일인지 구분하기 위한 변수입니다
이 코드가 실행되면 아래 사진처럼 맨 뒤에 : True가 붙습니다

html = open(savepath, "r", encoding="utf-8").read()
-> 파일을 다루는 코드입니다
open(파일 경로, 파일 모드 , 인코딩방식)
파일을 저장할 위치는 savepath , 파일모드는 읽기모드( r ) , 인코딩 방식은 utf-8로 했습니다
그리고 .read()로 파일을 읽습니다 그후에 읽은 데이터를 html 이라는 변수에 넣습니다
links = enum_links(html, url)
-> 위에서 만든 enum_links 함수를 실행합니다 (url내부의 링크를 추출하는 함수)
그 후에 enum_links에서 받는 retrun result 값을 links 변수에 넣습니다
for link_url in links:
if link_url.find(root_url) != 0:
if not re.search(r".css$", link_url): continue
if re.search(r".(html|htm)$", link_url):
analyze_html(link_url, root_url)
continue
download_file(link_url)
->링크가 루트 이외의 경로를 나타내면 무시합니다
다만 css파일의 경우에는 다운받지 않으면 레이아웃이 깨지므로 다운받습니다
----------------------------------------------------------------------------------------------------
if __name__ == "__main__":
url = "https://docs.python.org/ko/3/"
analyze_html(url, url)
->이 프로그램의 시작점입니다
url에는 정보를 얻고자 하는 사이트의 주소를 넣습니다
(저는 파이썬 문서의 주소를 입력했습니다)
그 후에 analyze_html 함수를 실행합니다
-결과-
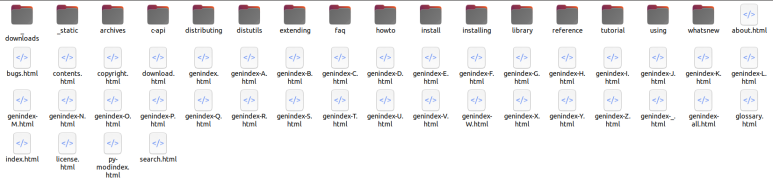
*코드를 실행하여 페이지내 각종 파일,폴더를 다운받은 상태
'Python' 카테고리의 다른 글
| 파이썬 cron으로 정기적으로 프로그램 실행하기 (0) | 2022.09.07 |
|---|---|
| 5) 파이썬 API으로 전세계 날씨정보 얻기 (0) | 2022.09.05 |
| 3)파이썬 크롤링으로 뉴스정보 수집하기(Beautifulsoup - select) (1) | 2022.09.02 |
| 2)파이썬 크롤링으로 네이버 환율,금 시세,유가,증시 등등 정보 추출하기(Beautifulsoup - select_one) (1) | 2022.08.24 |
| 1)파이썬 크롤링으로 기상청 날씨정보 얻어오기(Beautifulsoup - find) (0) | 2022.08.22 |



